Hosting on GitHub Pages? Watch out for Subdomain Hijacking
A friend messaged me late last night with the scary news that Google had emailed him about a ton of spammy subdomains on his own domain.
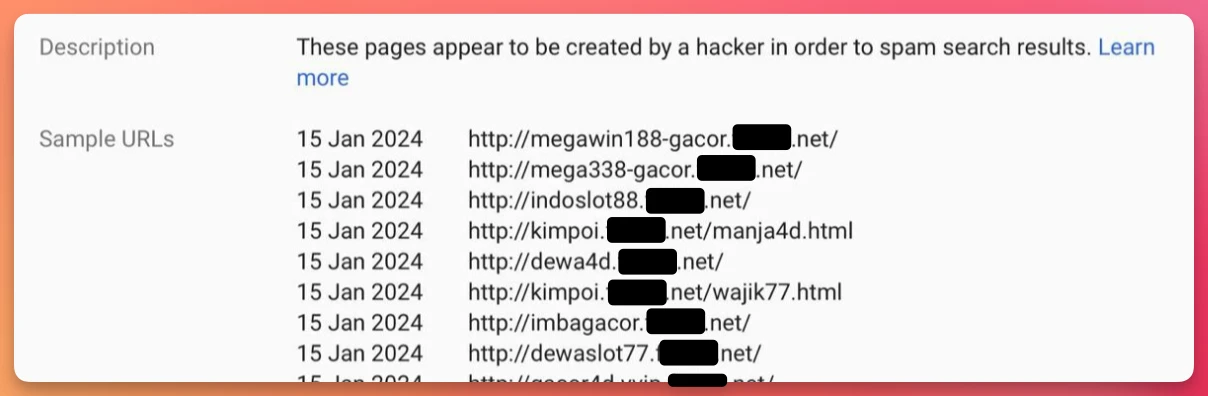
Any idea how this could have happened, he asked?
A friend messaged me late last night with the scary news that Google had emailed him about a ton of spammy subdomains on his own domain.
Any idea how this could have happened, he asked?
Why should the Java folk have all the fun?!
My friend and colleague Gunnar Morling launched a fun challenge this week: how fast can you aggregate and summarise a billion rows of data? Cunningly named The One Billion Row Challenge (1BRC for short), it’s aimed at Java coders to look at new features in the language and optimisation techniques.
Not being a Java coder myself, and seeing how the challenge has already unofficially spread to other communities including Rust and Python I thought I’d join in the fun using what I know best: SQL.
Antora is a modern documentation site generator with many nice features including sourcing documentation content from one or more separate git repositories. This means that your docs can be kept under source control (yay 🎉) and in sync with the code of the product that they are documenting (double yay 🎉🎉).
As you would expect for a documentation tool, the Antora documentation is thorough but there was one sharp edge involving GitHub that caught me out which I’ll detail here.
AI, what a load of hyped-up bollocks, right? Yet here I am, legit writing a blog about it and not for the clickbait but…gasp…because it’s actually useful.
Used correctly, it’s just like any other tool on your desktop. It helps you get stuff done quicker, better—or both.
As a newcomer to Apache Flink one of the first things I did was join the Slack community (which is vendor-neutral and controlled by the Flink PMC). At the moment I’m pretty much in full-time lurker mode, soaking up the kind of questions that people have and how they’re using Flink.
One question that caught my eye was from Marco Villalobos, in which he asked about the Flink JDBC driver and a SQLDataException he was getting with a particular datatype. Now, unfortunately, I have no idea about the answer to this question—but the idea of a JDBC driver through which Flink SQL could be run sounded like a fascinating path to follow after previously looking at the SQL Client.
Sometimes you might want to access Apache Kafka that’s running on your local machine from another device not on the same network. I’m not sure I can think of a production use-case, but there are a dozen examples for sandbox, demo, and playground environments.
In this post we’ll see how you can use ngrok to, in their words, Put localhost on the internet. And specifically, your local Kafka broker on the internet.
When I started my journey learning Apache Flink one of the things that several people expressed an interest in hearing more about was PyFlink. This appeals to me too, because whilst Java is just something I don’t know and feels beyond me to try and learn, Python is something that I know enough of to at least hack my way around it. I’ve previously had fun with PySpark, and whilst Flink SQL will probably be one of my main focusses, I also want to get a feel for PyFlink.
The first step to using PyFlink is installing it - which should be simple, right?
So far I’ve plotted out a bit of a map for my exploration of Apache Flink, looked at what Flink is, and run my first Flink application. Being an absolutely abysmal coder—but knowing a thing or two about SQL—I figure that Flink SQL is where my focus is going to lie (I’m also intrigued by PyFlink, but that’s for another day…).
🎉 I just ran my first Apache Flink cluster and application on it 🎉
A brief diversion from my journey learning Apache Flink to document an interesting zsh oddity that briefly tripped me up:
cd: string not in pwd: flink-1.17.1
My journey with Apache Flink begins with an overview of what Flink actually is.
What better place to start than the Apache Flink website itself:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Like a fortunate child on Christmas Day, I’ve got a brand new toy! A brand new—to me—open-source technology to unwrap, learn, and perhaps even aspire to master elements of within.
I joined Decodable two weeks ago, and since Decodable is built on top of Apache Flink it seems like a great time to learn it. After six years learning Apache Kafka and hearing about this “Flink” thing but—for better or worse—never investigating it, I now have the perfect opportunity to do so.
Writing is one of the most powerful forms of communication, and it’s useful in a multitude of roles and contexts. As a blog-writing, documentation-authoring, twitter-shitposting DevEx engineer I spend a lot of my time writing. Recently, someone paid me a very nice compliment about a blog I’d written and asked how they could learn to write like me and what resources I’d recommend.
Never one to miss a chance to write and share something, here’s my response to this :)
This was originally titled more broadly “What Does A DevEx Engineer Do”, but that made it into a far too tedious and long-winding etymological exploration of the discipline. Instead, I’m going to tell you what this particular instantiation of the entity does 😄
Wordpress still, to an extent, rules the blogging world. Its longevity is testament to…something about it ;) However, it’s not my favourite platform in which to write a blog by a long way. It doesn’t support Markdown to the extent that I want. Yes, I’ve tried the plugins; no, they didn’t do what I needed.
I like to write all my content in a structured format - ideally Asciidoc, but I’ll settle for Markdown too. Here’s how I stayed [almost] sane whilst composing a blog in Markdown, reviewing it in Google Docs, and then publishing it in Wordpress in a non-lossy way.
One of the most important ways that a project can help its developers is providing them good documentation. Actually, scratch that. Great documentation.
java.lang.ClassNotFoundException: delta.DefaultSourceNo great insights in this post, just something for folk who Google this error after me and don’t want to waste three hours chasing their tails… 😄
Here’s a neat little trick you can use with DuckDB to convert a CSV file into a Parquet file:
COPY (SELECT *
FROM read_csv('~/data/source.csv',AUTO_DETECT=TRUE))
TO '~/data/target.parquet' (FORMAT 'PARQUET', CODEC 'ZSTD');
